Model Fit in Binary Response Models8
How to Measure Model Fit
There are quite a few model fit measures around for binary response models, such as pseudo R-Squared and the Akaike Information Criterion (AIC). What I am going to present here, however, is the so-called ROC curve, as I personally really don’t like the aforementioned measures.
What is it?
The principle idea of ROC is to determine how well our model is able to separate cases into the two categories of our dependent variable. It approaches this question by comparing the actual observed values of the dependent variable with the values the model would predict, given the values of the independent variables.
Consider Figure 15 a). On the x-axis you see eight observations, marked as coloured diamonds. Red diamonds represent countries which are dictatorships, and blue ones democracies. They are sorted by their respective level of per capita GDP. Now suppose that the displayed CDF is the results of a model we have estimated. With a cut off point \(\tau=0.5\) we would correctly predict the group of four observations on the left to be dictatorships. They are True Negatives (TN). The group on the right would be correctly predicted as democracies, these are True Positives (TP). We have no incorrectly classified cases; our model has been able to separate cases perfectly. You can see this represented in the form of distributions in panel b).
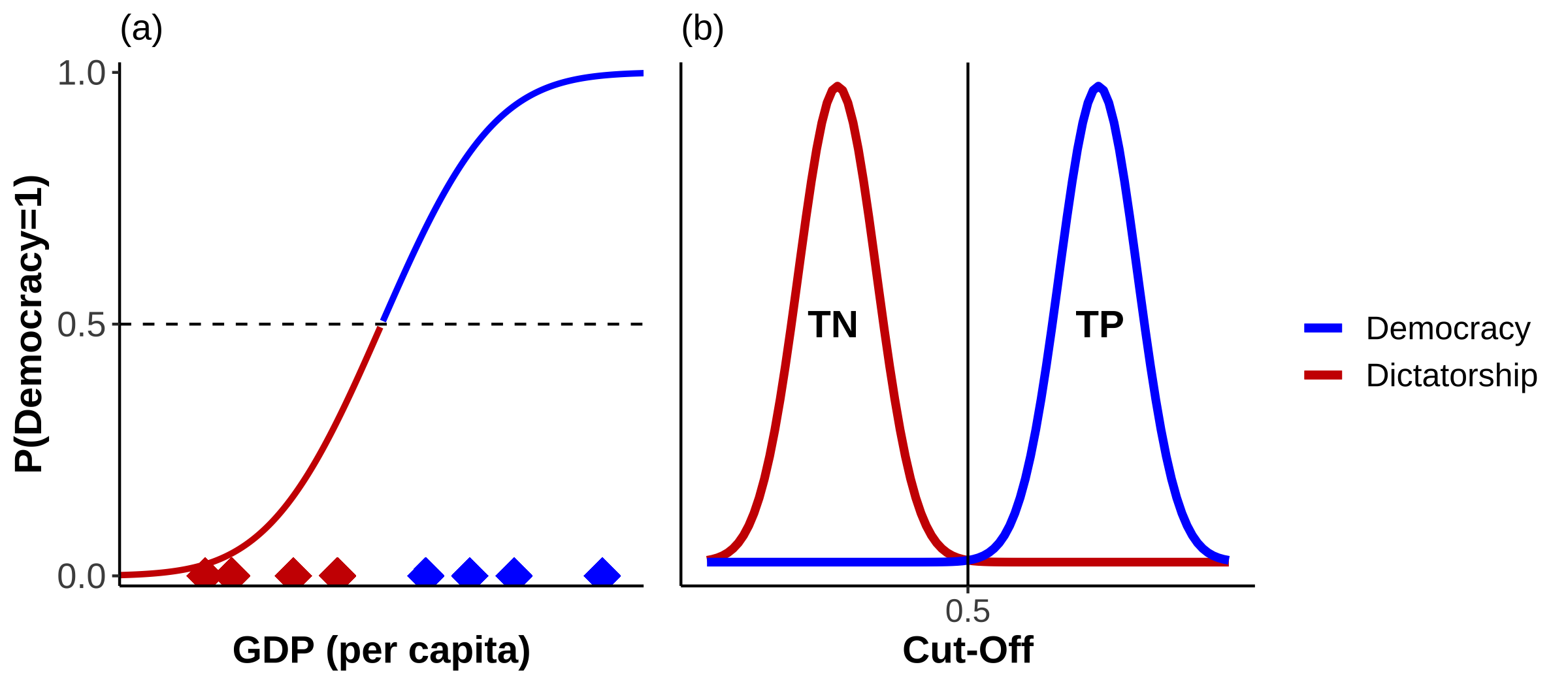
Figure 15: Perfect Separation
As you well know by now, the real world is oddly deficient in achieving perfection such as this. We will observe both poor democracies, and rich dictatorships. This scenario is shown in Figure 16 a).
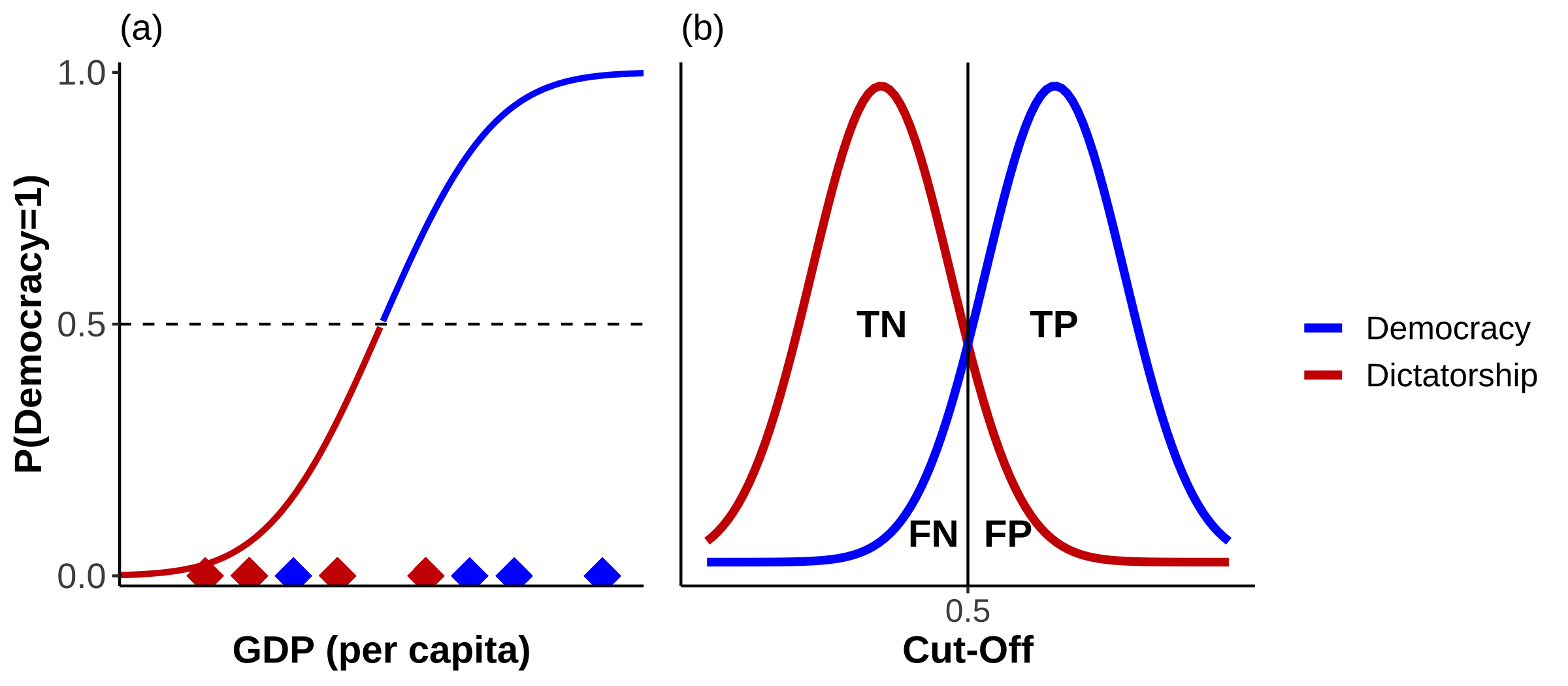
Figure 16: Overlap
According to the CDF we would predict the poor democracy as a dictatorship. It would be a False Negative (FN). Conversely, we would predict the rich dictatorship as a democracy and would obtain a False Positive (FP). The distribution of cases in Figure 16 b) is not as clearly separated any more as in Figure 15 b). Now they overlap, leading to incorrect classifications. These are marked accordingly in Figure 17. As we are no longer operating in a world in which we only have TNs and TPs, I think we can all agree that our model fit is no longer as good as in Figure 15.
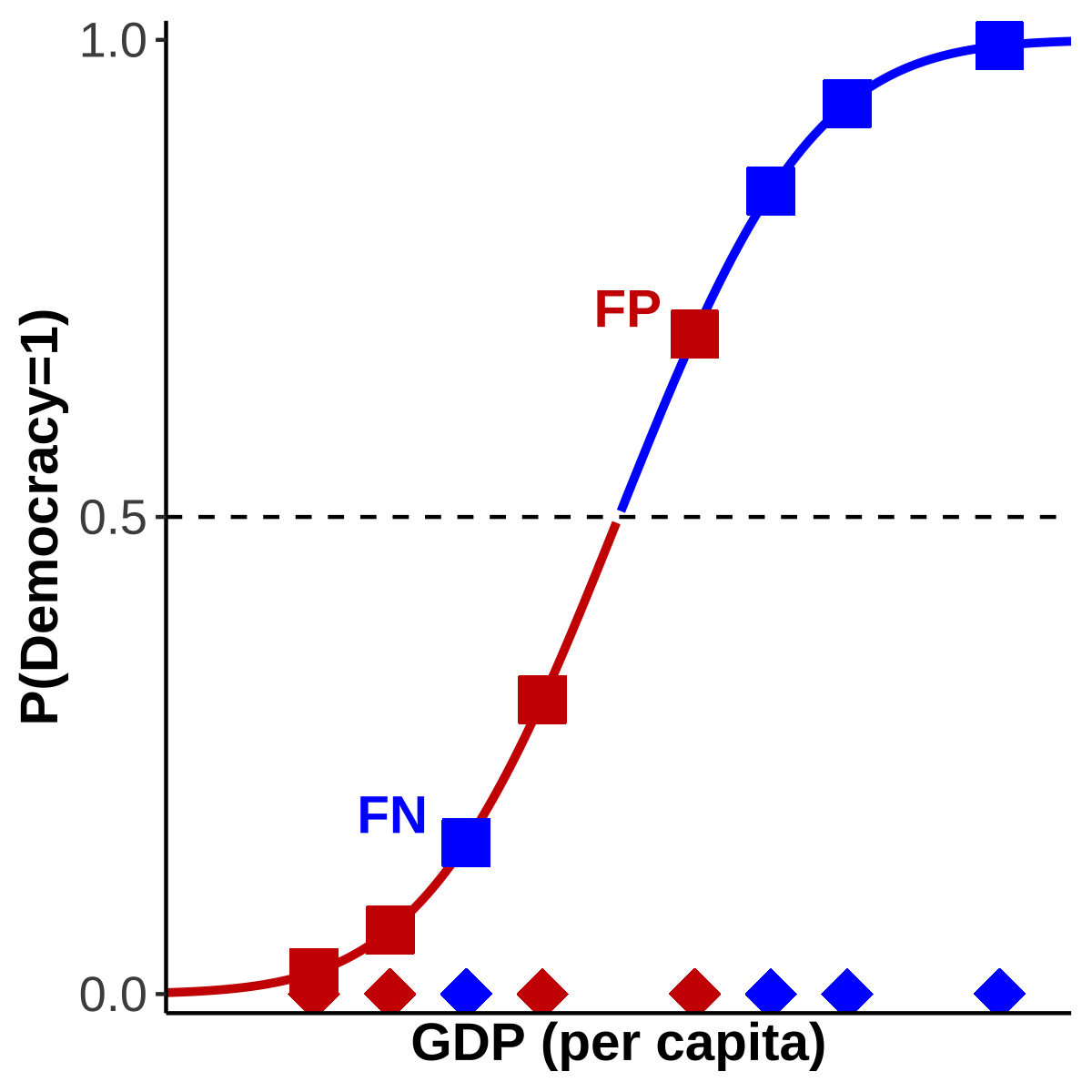
Figure 17: False Negatives and False Positives
But there is another issue: whilst setting \(\tau\) at 0.5 makes intuitive sense, there is nothing preventing us from shifting \(\tau\) around. Indeed, the number of FPs and FNs very much depends on where we place our cut-off point. For example, if we don’t want any FNs, then we just have to shift \(\tau\) sufficiently downwards. Or if we want to avoid FPs we only need to move it far enough upwards. I have illustrated this in Figure 18 a) and b), respectively.
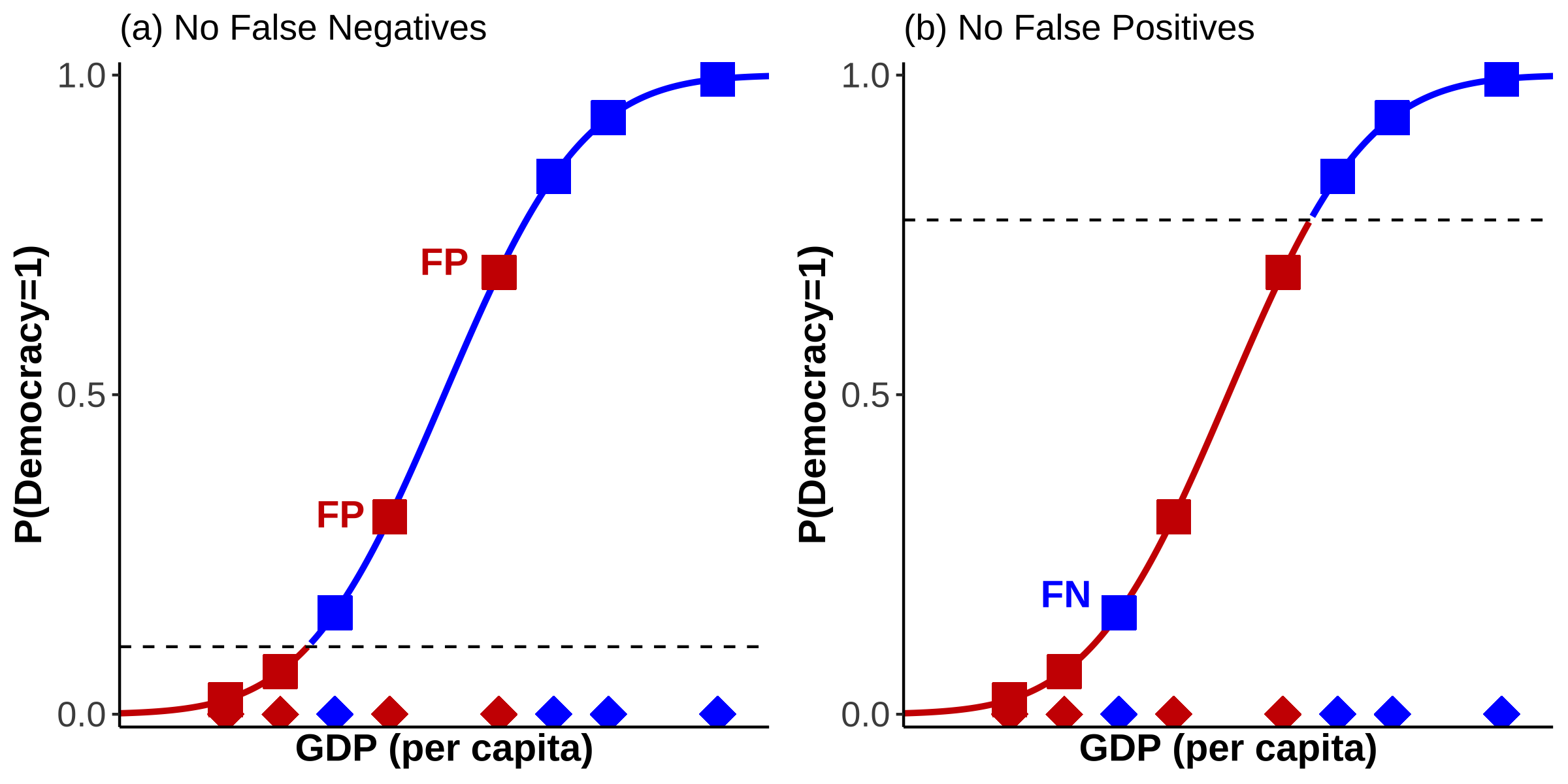
Figure 18: Shifting \(\tau\)
These are only three options of placing the threshold. But we have a total of eight observations which means that there are nine potential positions for the cut-off point with each leading to a different conclusion of how well our model fits the observed data. Let’s go through this more systematically and start by placing \(\tau\) at the very bottom. Because the number of TNs, TPs, FNs, and FPs will only change at the “next” observation we only need to shift as many times as there are observations. For each shift we record the values of all four quantities in a crosstabulation which is displayed in the following table:
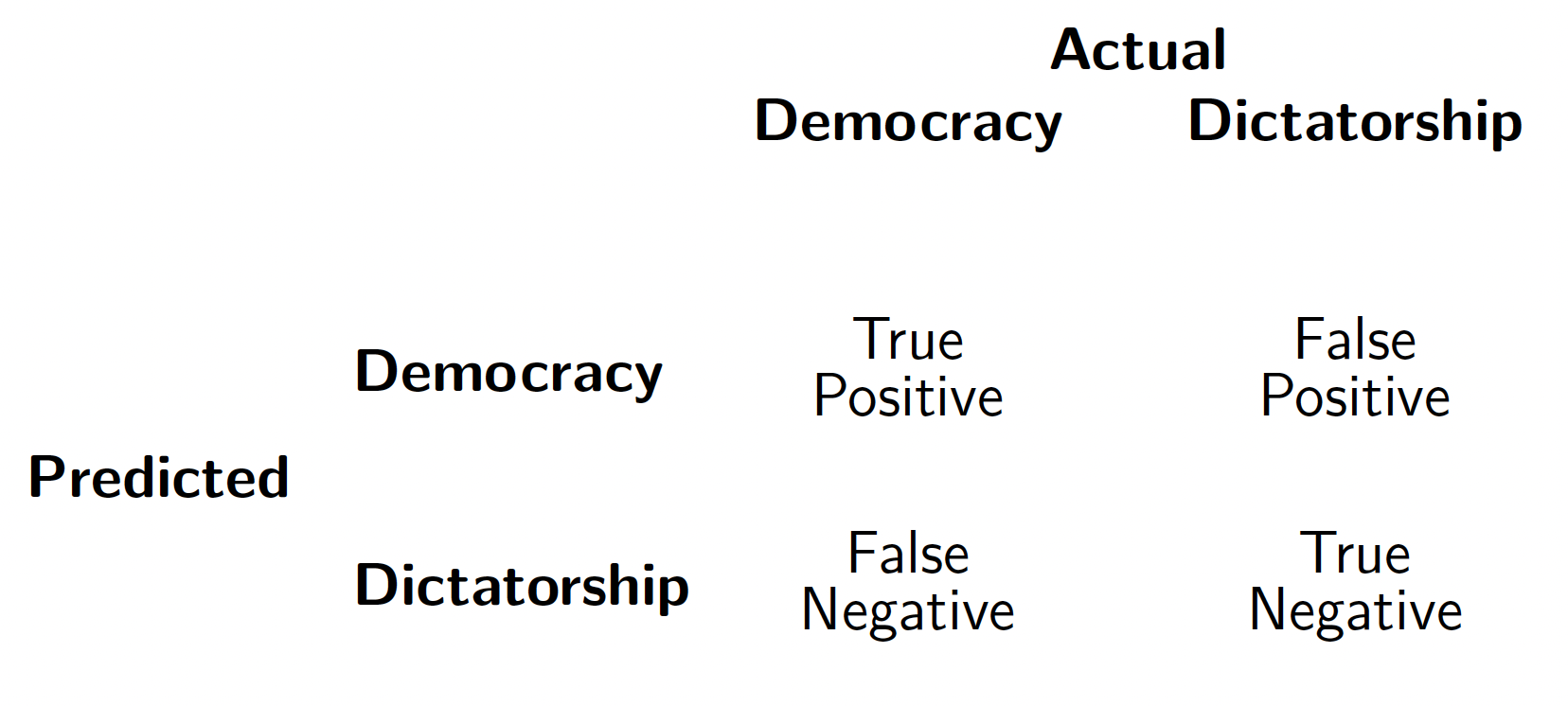
These tables are useful in their own right, but since we will end up with as many of them as there are observations, this can quickly get very messy. There are only eight observations here, but imagine doing these for the world data set with 190 observationsWe therefore need to find a way to condense the information contained in each of the n confusion matrices into a single measure. If you look closely, you will see that TNs and FPs form a close relationship: if we shift up \(\tau\) in Figure 18 a) we are reducing the number of FPs and obtain more TNs. As TPs relate in the same way to FNs, we can quantify their respective relationships in the following rates:
\[\begin{equation} \text{False Positive Rate}=\text{Sensitivity}=\frac{\text{False Positives}}{\text{False Positives}+\text{True Negatives}} \end{equation}\]
In our case you can think of the False Positive Rate (FPR) as the proportion of incorrectly specified dictatorships.
\[\begin{align} \text{True Positive Rate}&=1-\text{Specificity}=\frac{\text{True Positives}}{\text{True Positives}+\text{False Negatives}}\\[10pt] \text{Specificity} &=1-\text{True Positive Rate}=1-\frac{\text{TP}}{\text{TP}+\text{FN}} \nonumber \end{align}\]
For our example the True Positive Rate (TPR) represents the proportion of correctly specified democracies. If we calculate these rates for each of our n confusion matrices, we are already reducing four quantities into two. Let’s do it. To provide a visual aid in this rather laborious process, I have created Figure 19 which depicts all eight shifts.
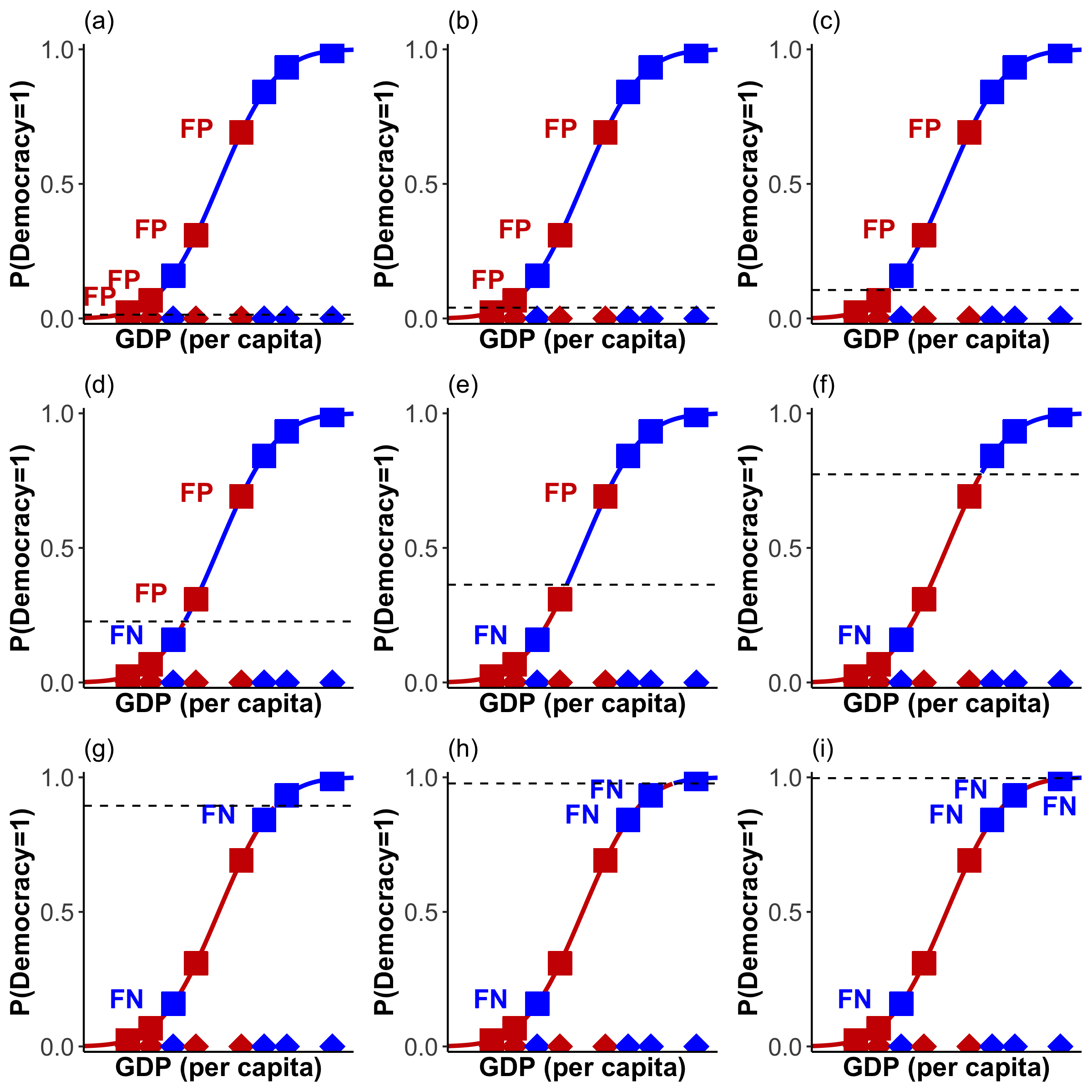
Figure 19: Towards the ROC Curve
The following table displays the confusion matrix for each of the panels in Figure 19, as well as the respective TPR and FPR (you are welcome).

As we only need the TPRs and FPRs going forward, it makes sense to collect these in their own little table:

We are nearly there! The last step is to display all these values in the form of a curve with the TPR on the y-axis, and the FPR on the x-axis. You can see the result – the ROC curve – in Figure 20 a).
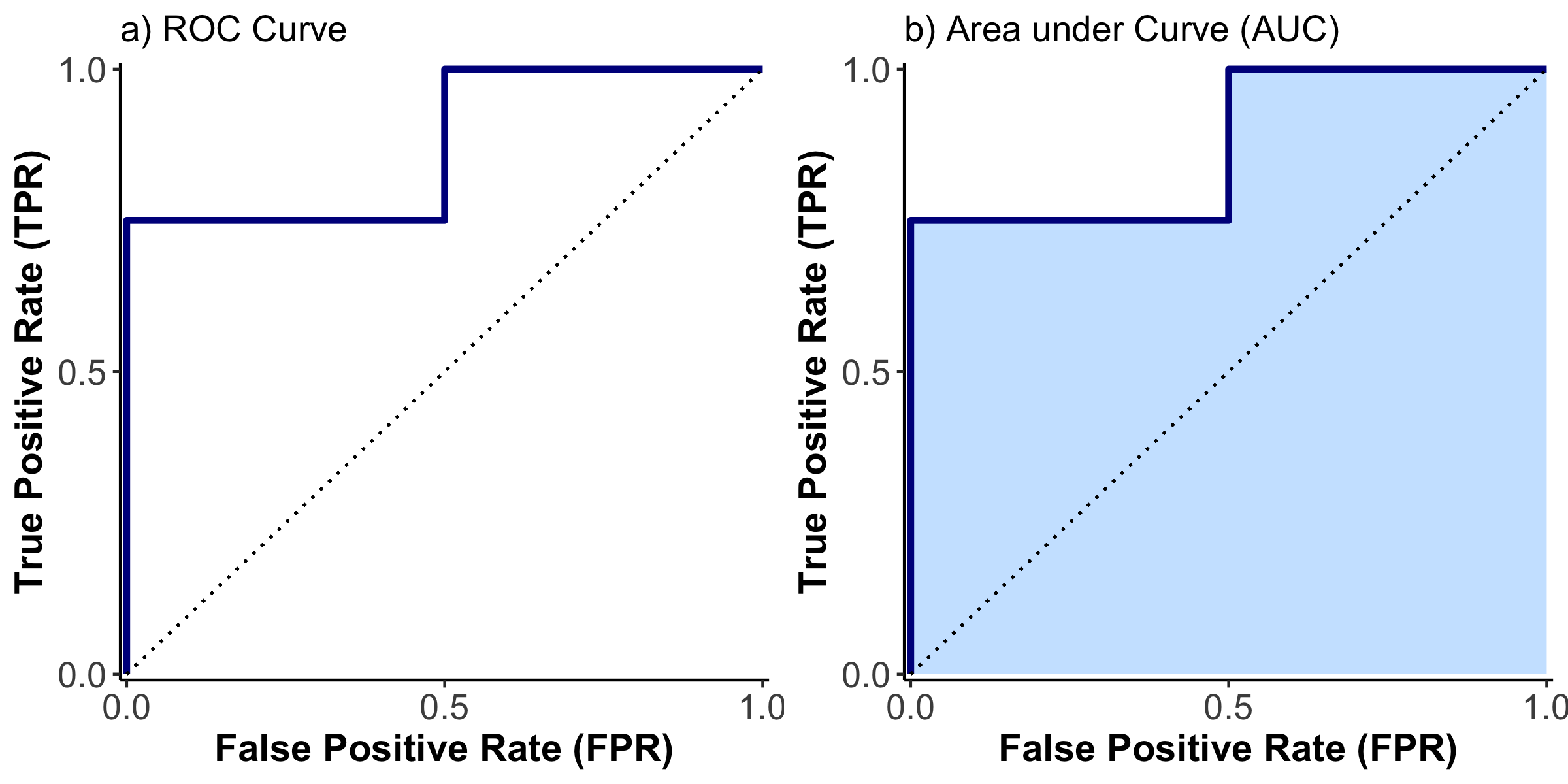
Figure 20: ROC Curve
Note that I have added a diagonal where TPR = FPR. This is sometimes described as a model without independent variables. I like to think of the line as the graphical point where our model would not be able to separate between the two categories, at all. The further the ROC curve is away from the diagonal, the better our model is at separating the two categories. But there are two sides to the diagonal. We want it to be above the diagonal, as here the model is predicting 0s as 0s and 1s as 1s. Underneath, the prediction is inverse and 0s are predicted as 1s, and 1s are predicted as 0s.
To summarize the position of the curve into a numerical expression, the Area Under Curve (AUC) is used, as shown in Figure 20 b). If the area is 100% we are correctly predicting everything. At 50% the model is incapable of separation, and at 0% the model gets everything wrong. This is very useful to compare different models.
R
How do you do all of this in R? Let’s start with the simple emergence model. In order to calculate a ROC curve, we need a new package, called pROC. Install it and load it.
To calculate the ROC curve, we need a few steps:
prob_em <- predict(emergence, type="response")
world_democ0$prob_em <- unlist(prob_em)
roc <- roc(world_democ0$democracy, world_democ0$prob_em)
auc(roc)
Area under the curve: 0.5048What does each line do?
- predict the probability of democratic emergence for each observation (country year) and store them in a new vector called
prob_em. - add the vector
prob_emto the data frameworld_democ0. In order to do this, we need tounlistthe values in theprob_emvector. - we then call the
rocfunction inw hich we compare the predicted probabilities (world_democ0$prob_em) with the actual, observed regime type (world_democ0$democracy) and store the result in an object calledroc - as a last step we calculate the area under the curve with the
auc()function
But we can also plot the ROC curve:
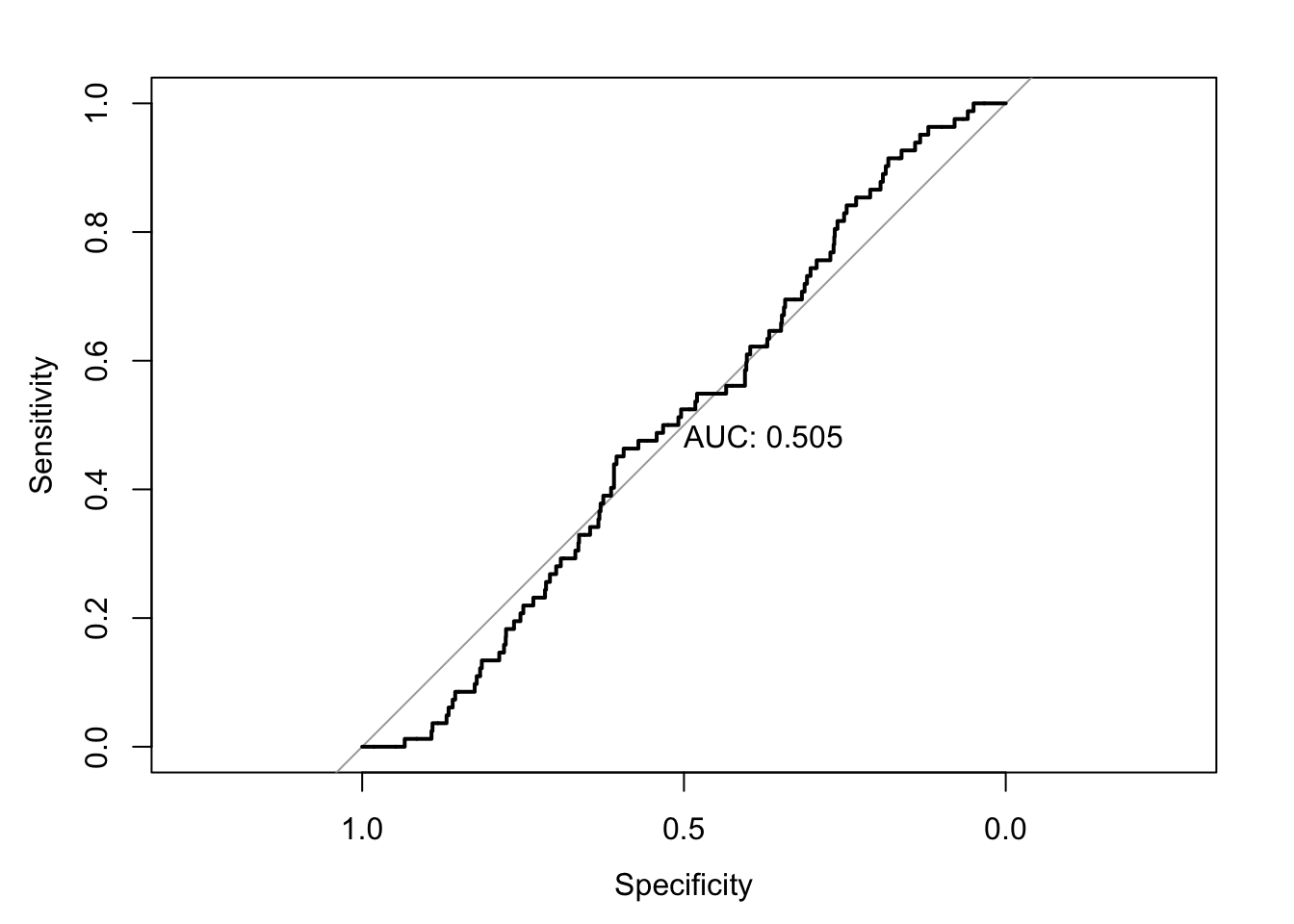
Note that print.auc=TRUE prints the numerical value into this plot. You can suppress it by setting it to FALSE.
Let’s follow this procedure for the other models.
Emergence: Full Model
prob_em_full <- predict(emergence_full, type="response")
world_democ0$prob_em_full <- unlist(prob_em_full)
roc <- roc(world_democ0$democracy, world_democ0$prob_em_full)
auc(roc)
Area under the curve: 0.5932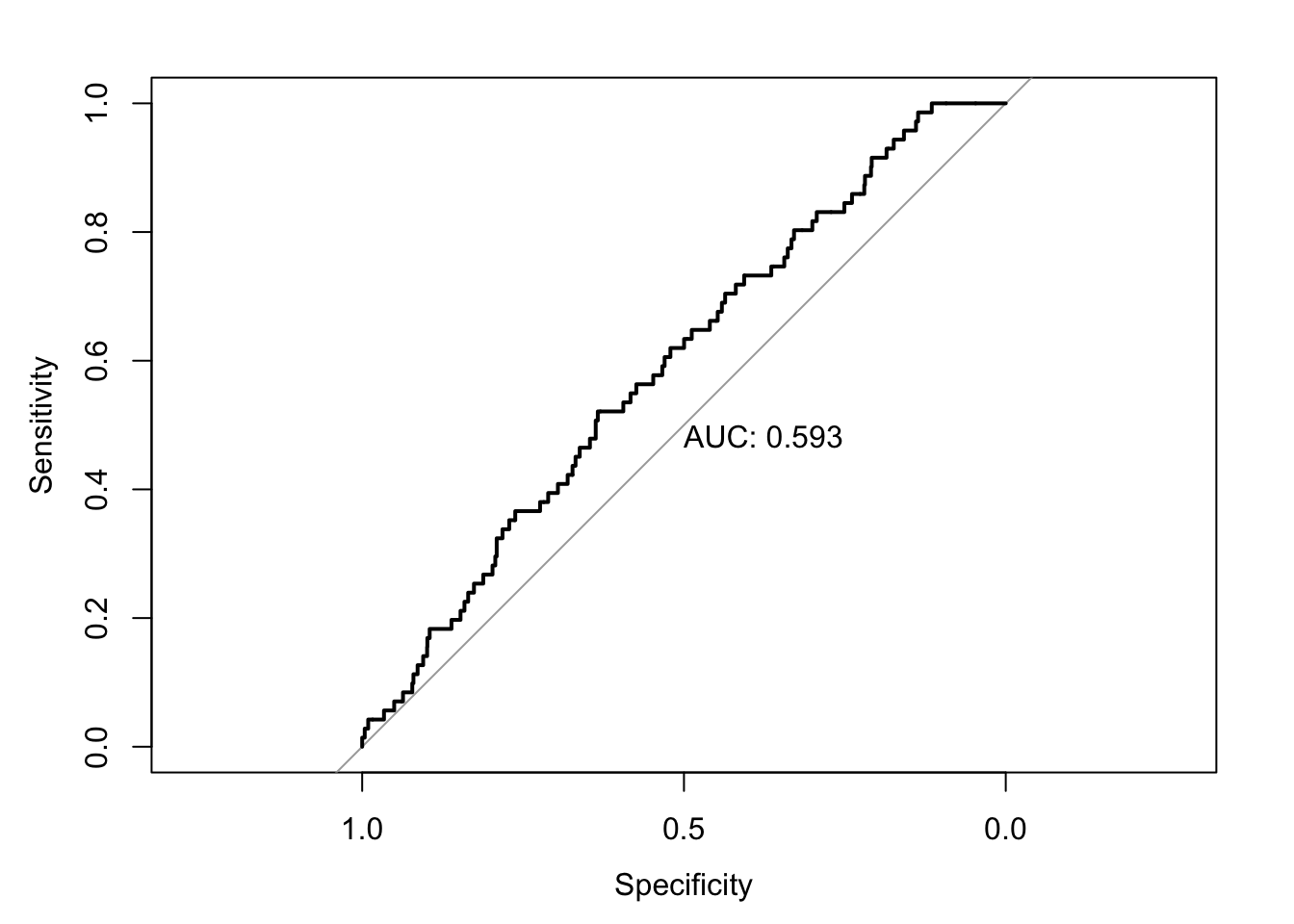
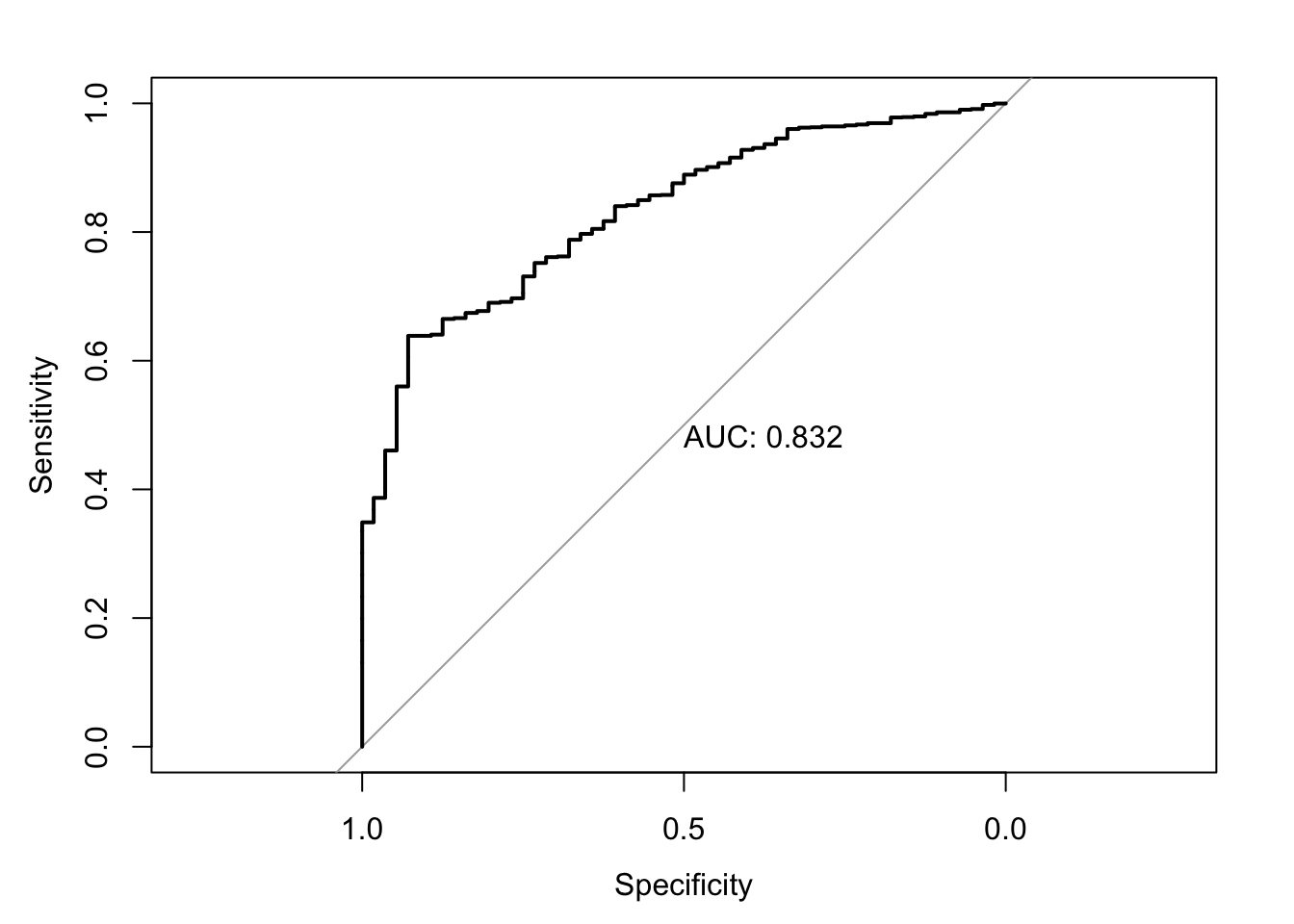
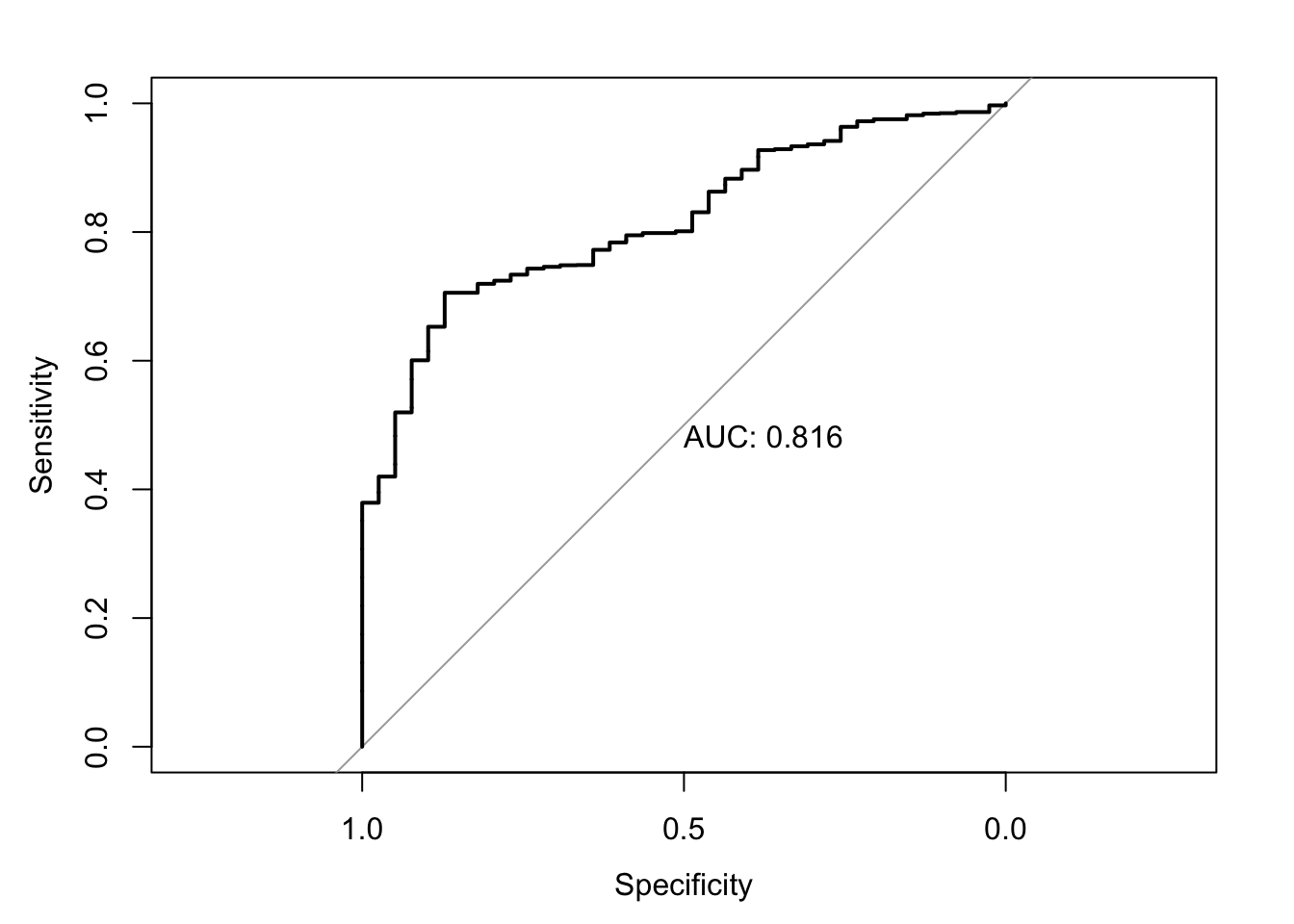
This is a verbatim reproduction from Reiche (forthcoming). The text is based on an explanatory video by StatQuest with Josh Starmer. All figures are copyrighted.↩︎